ChatGPT Predicts In-Hospital All-Cause Mortality for Sepsis: In-Context Learning with the Korean Sepsis Alliance Database
- Oh N
 1
1 - Cha WC2
- Seo JH3
- Choi SG1
- Kim JM1
- Chung CR4
- Suh GY4,5
- Lee SY6
- Oh DK6
- Park MH6
- Lim CM6
- Ko RE4
- Korean Sepsis Alliance1
- Affiliations
-
- 1Department of Surgery, Samsung Medical Center, Sungkyunkwan University School of Medicine, Seoul, Korea
- 2Department of Emergency Medicine, Samsung Medical Center, Sungkyunkwan University School of Medicine, Seoul, Korea
- 3Department of Digital Health, Samsung Advanced Institute for Health Science & Technology, Sungkyunkwan University, Seoul, Korea
- 4Department of Critical Care Medicine, Samsung Medical Center, Sungkyunkwan University School of Medicine, Seoul, Korea
- 5Division of Pulmonary and Critical Care Medicine, Department of Medicine, Samsung Medical Center, Sungkyunkwan University, Seoul, Korea
- 6Division of Pulmonology and Critical Care Medicine, Department of Internal Medicine, Asan Medical Center, University of Ulsan College of Medicine, Seoul, Korea
- KMID: 2558322
- DOI: http://doi.org/10.4258/hir.2024.30.3.266
Abstract
Objectives
Sepsis is a leading global cause of mortality, and predicting its outcomes is vital for improving patient care. This study explored the capabilities of ChatGPT, a state-of-the-art natural language processing model, in predicting in-hospital mortality for sepsis patients.
Methods
This study utilized data from the Korean Sepsis Alliance (KSA) database, collected between 2019 and 2021, focusing on adult intensive care unit (ICU) patients and aiming to determine whether ChatGPT could predict all-cause mortality after ICU admission at 7 and 30 days. Structured prompts enabled ChatGPT to engage in in-context learning, with the number of patient examples varying from zero to six. The predictive capabilities of ChatGPT-3.5-turbo and ChatGPT-4 were then compared against a gradient boosting model (GBM) using various performance metrics.
Results
From the KSA database, 4,786 patients formed the 7-day mortality prediction dataset, of whom 718 died, and 4,025 patients formed the 30-day dataset, with 1,368 deaths. Age and clinical markers (e.g., Sequential Organ Failure Assessment score and lactic acid levels) showed significant differences between survivors and non-survivors in both datasets. For 7-day mortality predictions, the area under the receiver operating characteristic curve (AUROC) was 0.70–0.83 for GPT-4, 0.51–0.70 for GPT-3.5, and 0.79 for GBM. The AUROC for 30-day mortality was 0.51–0.59 for GPT-4, 0.47–0.57 for GPT-3.5, and 0.76 for GBM. Zero-shot predictions using GPT-4 for mortality from ICU admission to day 30 showed AUROCs from the mid-0.60s to 0.75 for GPT-4 and mainly from 0.47 to 0.63 for GPT-3.5.
Conclusions
GPT-4 demonstrated potential in predicting short-term in-hospital mortality, although its performance varied across different evaluation metrics.
Figure
-
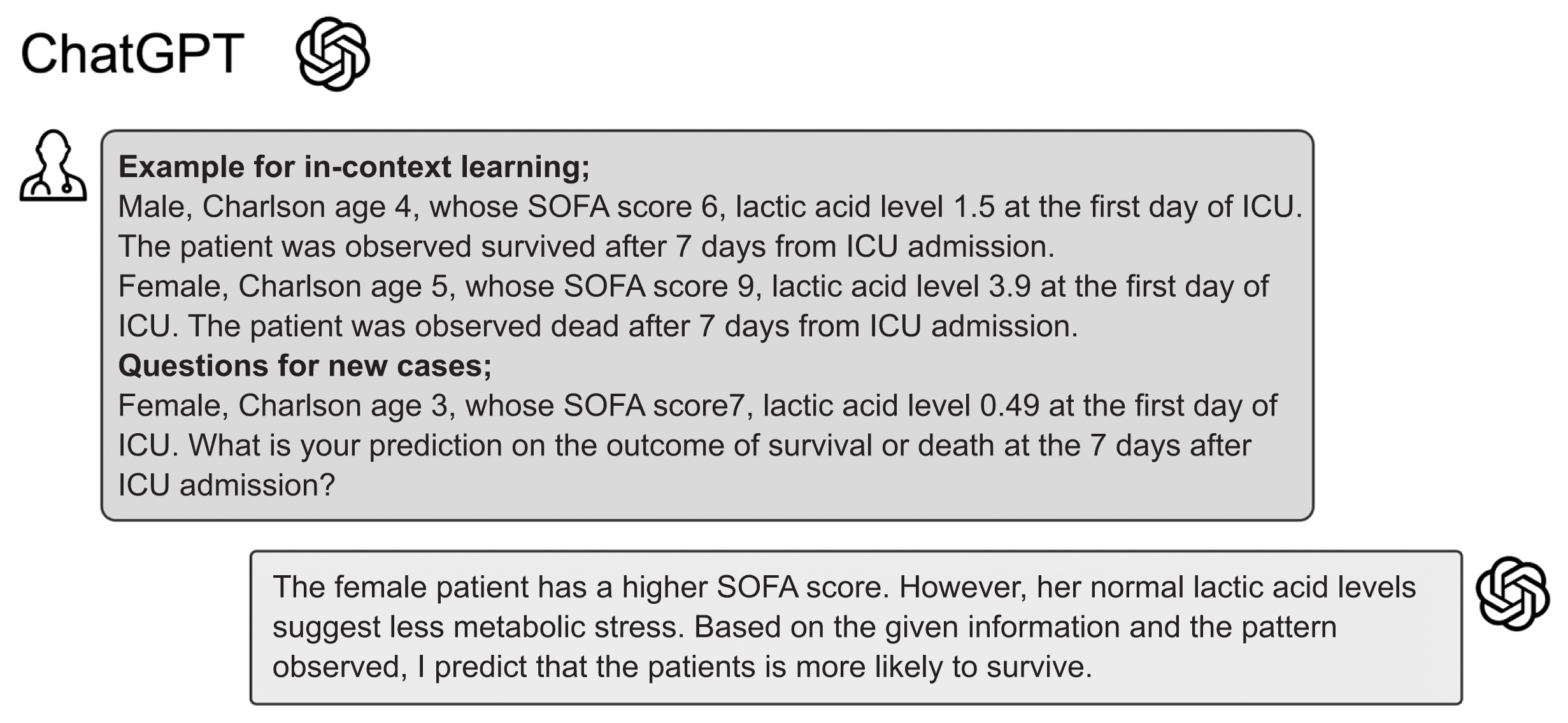
Figure 1 Example of in-context learning and prediction using ChatGPT. This figure illustrates the method of in-context learning and subsequent prediction using ChatGPT for assessing sepsis outcomes in ICU patients. It presents an example of how the model was provided with specific patient data, including age (age score in Charlson Comorbidity Index), SOFA score, and lactic acid levels at the time of ICU admission, along with the known outcomes after 7 days. SOFA: Sequential Organ Failure Assessment, ICU: intensive care unit.
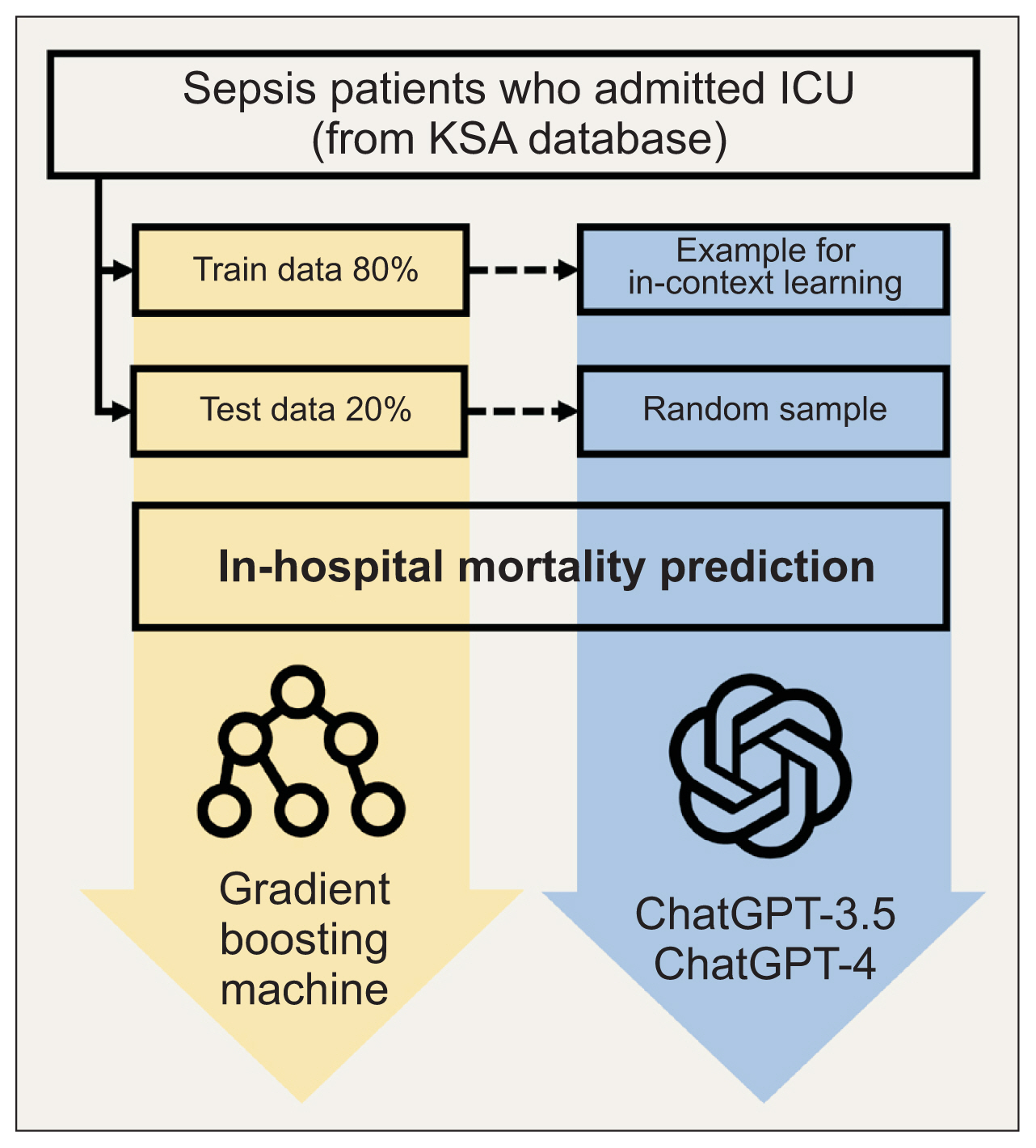
Figure 2 Experimental design. The Korean Sepsis Alliance (KSA) database was utilized to conduct an experiment to predict in-hospital mortality for patients admitted to the intensive care unit (ICU). The predictive performance of gradient boosting machine, ChatGPT-3.5, and ChatGPT-4 were compared.
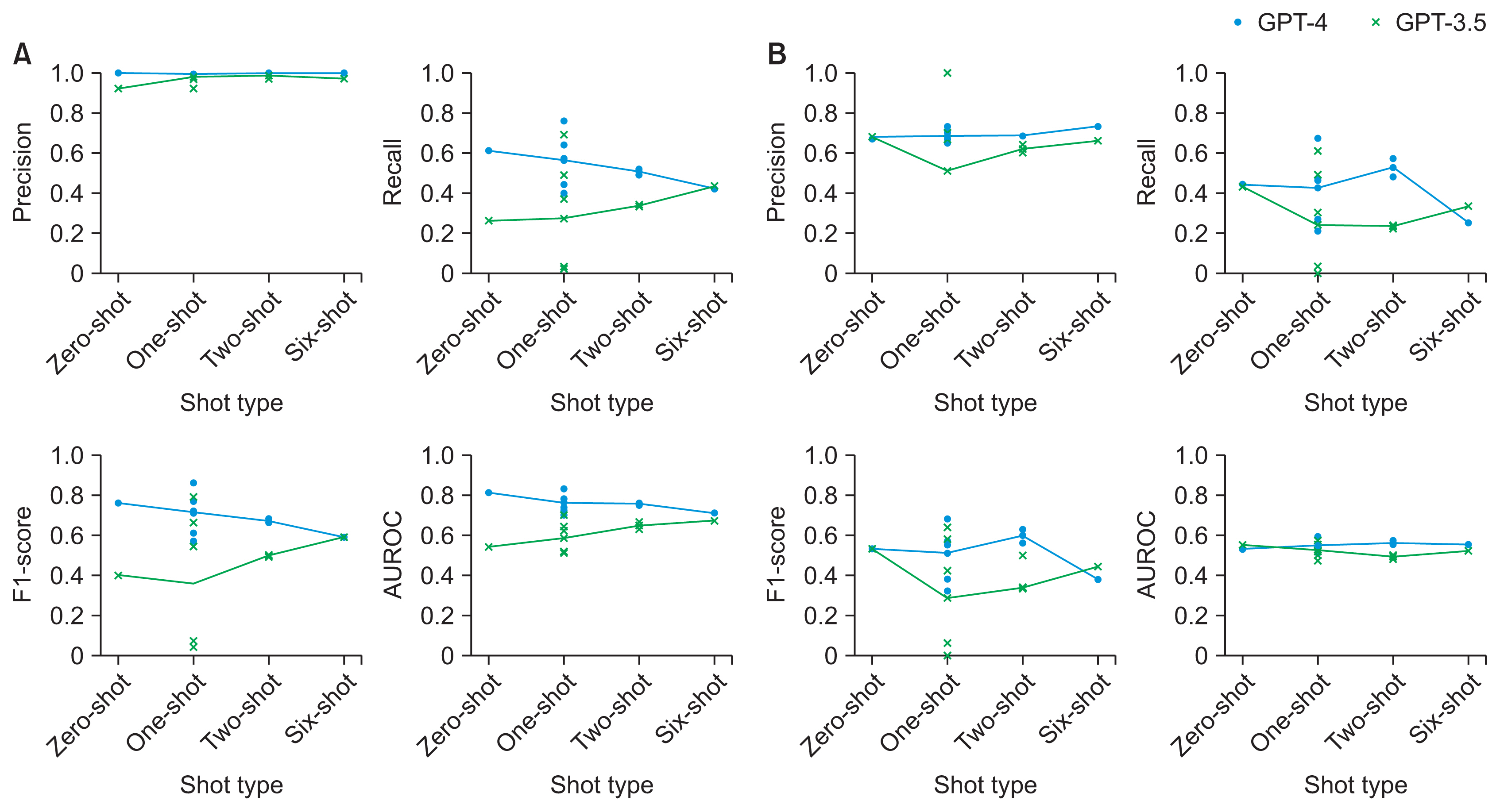
Figure 3 Performance evaluations of the GPT-4 and GPT-3.5 for predicting all-cause mortality before discharge by (A) day 7 and (B) day 30, with accuracy, precision, recall, F1-score, and AUROC. Changes in predictive performance are shown as the number of examples for in-context learning varies. AUROC, area under curve of the receiver operating characteristic.
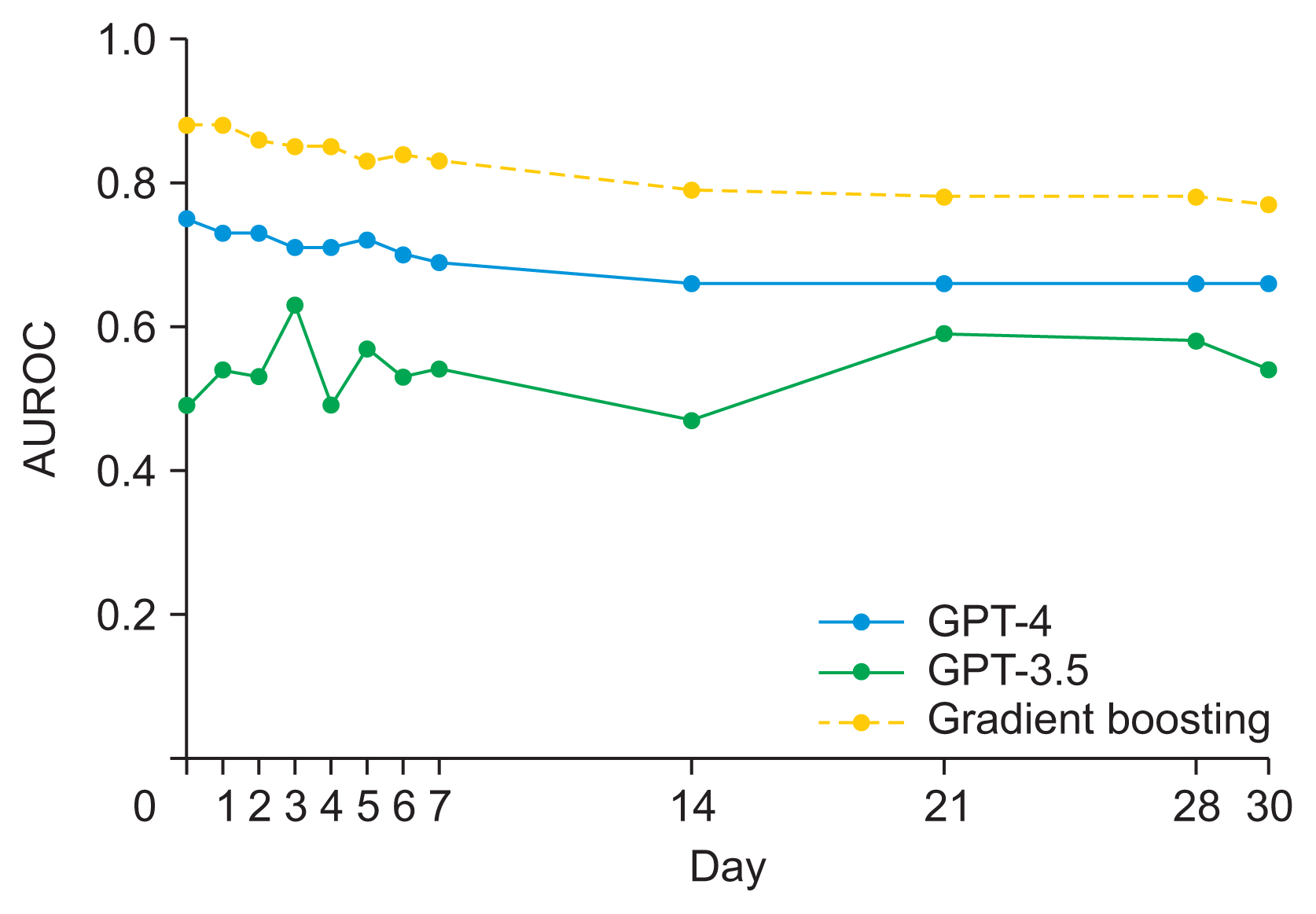
Figure 4 Temporal dependency in the predictive performance of the GPT-4, GPT-3.5, and gradient boosting machine (GBM). GPT-4 and GPT-3.5 were tested with zero shots, while GBM was trained with 80% of the dataset and tested with 20% of the dataset. Thus, a simple performance comparison between ChatGPT and GBM should be interpreted with caution. AUROC, area under curve of the receiver operating characteristic.
Reference
-
References
1. Singer M, Deutschman CS, Seymour CW, Shankar-Hari M, Annane D, Bauer M, et al. The Third International Consensus Definitions for Sepsis and Septic Shock (Sepsis-3). JAMA. 2016; 315(8):801–10. https://doi.org/10.1001/jama.2016.0287.
Article2. Fleischmann C, Scherag A, Adhikari NK, Hartog CS, Tsaganos T, Schlattmann P, et al. Assessment of global incidence and mortality of hospital-treated sepsis. current estimates and limitations. Am J Respir Crit Care Med. 2016; 193(3):259–72. https://doi.org/10.1164/rccm.201504-0781OC.
Article3. Sakr Y, Jaschinski U, Wittebole X, Szakmany T, Lipman J, Namendys-Silva SA, et al. Sepsis in intensive care unit patients: worldwide data from the intensive care over nations audit. Open Forum Infect Dis. 2018; 5(12):ofy313. https://doi.org/10.1093/ofid/ofy313.
Article4. Hu C, Li L, Huang W, Wu T, Xu Q, Liu J, et al. Interpretable machine learning for early prediction of prognosis in sepsis: a discovery and validation study. Infect Dis Ther. 2022; 11(3):1117–32. https://doi.org/10.1007/s40121-022-00628-6.5. Park H, Lee J, Oh DK, Park MH, Lim CM, Lee SM, et al. Serial evaluation of the serum lactate level with the SOFA score to predict mortality in patients with sepsis. Sci Rep. 2023; 13(1):6351. https://doi.org/10.1038/s41598-023-33227-7.
Article6. van Doorn WP, Stassen PM, Borggreve HF, Schalkwijk MJ, Stoffers J, Bekers O, et al. A comparison of machine learning models versus clinical evaluation for mortality prediction in patients with sepsis. PLoS One. 2021; 16(1):e0245157. https://doi.org/10.1371/journal.pone.0245157.
Article7. OpenAI. GPT-4 technical report [Internet]. Ithaca (NY): arXiv.org;2023. [cited at 2023 Dec 1]. Available from: https://arxiv.org/abs/2303.08774.8. Oh N, Choi GS, Lee WY. ChatGPT goes to the operating room: evaluating GPT-4 performance and its potential in surgical education and training in the era of large language models. Ann Surg Treat Res. 2023; 104(5):269–73. https://doi.org/10.4174/astr.2023.104.5.269.
Article9. Gilson A, Safranek CW, Huang T, Socrates V, Chi L, Taylor RA, et al. How does ChatGPT perform on the United States Medical Licensing Examination (USMLE)?: the implications of large language models for medical education and knowledge assessment. JMIR Med Educ. 2023; 9:e45312. https://doi.org/10.2196/45312.
Article10. Mihalache A, Popovic MM, Muni RH. Performance of an artificial intelligence chatbot in ophthalmic knowledge assessment. JAMA Ophthalmol. 2023; 141(6):589–97. https://doi.org/10.1001/jamaophthalmol.2023.1144.
Article11. Jeon K, Na SJ, Oh DK, Park S, Choi EY, Kim SC, et al. Characteristics, management and clinical outcomes of patients with sepsis: a multicenter cohort study in Korea. Acute Crit Care. 2019; 34(3):179–91. https://doi.org/10.4266/acc.2019.00514.
Article12. Rooke C, Smith J, Leung KK, Volkovs M, Zuberi S. Temporal dependencies in feature importance for time series predictions [Internet]. Ithaca (NY): arXiv.org;2021. [cited at 2024 Jul 10]. Available from: https://doi.org/10.48550/arXiv.2107.14317.
Article13. Theissler A, Spinnato F, Schlegel U, Guidotti R. Explainable AI for time series classification: a review, taxonomy and research directions. IEEE Access. 2022; 10:100700–24. https://doi.org/10.1109/ACCESS.2022.3207765.
Article14. Brown T, Mann B, Ryder N, Subbiah M, Kaplan JD, Dhariwal P, et al. Language models are few-shot learners. Adv Neural Inf Process Syst. 2020; 33:1877–901.15. Liu H, Tam D, Muqeeth M, Mohta J, Huang T, Bansal M, et al. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. Adv Neural Inf Process Syst. 2022; 35:1950–65.16. Min S, Lyu X, Holtzman A, Artetxe M, Lewis M, Hajishirzi H, et al. Rethinking the role of demonstrations: what makes in-context learning work? [Internet]. Ithaca (NY): arXiv.org;2022. [cited at 2024 Jul 10]. Available from: https://doi.org/10.48550/arXiv.2202.12837.
Article17. Friedman JH. Greedy function approximation: a gradient boosting machine. Ann Stat. 2001; 29(5):1189–232. https://doi.org/10.1214/aos/1013203451.18. Zhang Z, Zhao Y, Canes A, Steinberg D, Lyashevska O. written on behalf of AME Big-Data Clinical Trial Collaborative Group. Predictive analytics with gradient boosting in clinical medicine. Ann Transl Med. 2019; 7(7):152. https://doi.org/10.21037/atm.2019.03.29.
Article19. Ray PP. ChatGPT: a comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet Things Cyber Phys Syst. 2023; 3:121–54. https://doi.org/10.1016/j.iotcps.2023.04.003.
Article20. Sanderson M, Chikhani M, Blyth E, Wood S, Moppett IK, McKeever T, et al. Predicting 30-day mortality in patients with sepsis: an exploratory analysis of process of care and patient characteristics. J Intensive Care Soc. 2018; 19(4):299–304. https://doi.org/10.1177/1751143718758975.
Article21. Burdick H, Pino E, Gabel-Comeau D, McCoy A, Gu C, Roberts J, et al. Effect of a sepsis prediction algorithm on patient mortality, length of stay and readmission: a prospective multicentre clinical outcomes evaluation of real-world patient data from US hospitals. BMJ Health Care Inform. 2020; 27(1):e100109. https://doi.org/10.1136/bmjhci-2019-100109.
Article22. Wu Y, Huang S, Chang X. Understanding the complexity of sepsis mortality prediction via rule discovery and analysis: a pilot study. BMC Med Inform Decis Mak. 2021; 21(1):334. https://doi.org/10.1186/s12911-021-01690-9.23. Islam MM, Nasrin T, Walther BA, Wu CC, Yang HC, Li YC. Prediction of sepsis patients using machine learning approach: a meta-analysis. Comput Methods Programs Biomed. 2019; 170:1–9. https://doi.org/10.1016/j.cmpb.2018.12.027.
Article24. Kong G, Lin K, Hu Y. Using machine learning methods to predict in-hospital mortality of sepsis patients in the ICU. BMC Med Inform Decis Mak. 2020; 20(1):251. https://doi.org/10.1186/s12911-020-01271-2.
Article25. Li K, Shi Q, Liu S, Xie Y, Liu J. Predicting in-hospital mortality in ICU patients with sepsis using gradient boosting decision tree. Medicine (Baltimore). 2021; 100(19):e25813. https://doi.org/10.1097/MD.0000000000025813.
Article26. Jiang LY, Liu XC, Nejatian NP, Nasir-Moin M, Wang D, Abidin A, et al. Health system-scale language models are all-purpose prediction engines. Nature. 2023; 619(7969):357–62. https://doi.org/10.1038/s41586-023-06160-y.
Article27. Haleem A, Javaid M, Singh RP. An era of ChatGPT as a significant futuristic support tool: a study on features, abilities, and challenges. BenchCouncil Trans Benchmarks Stand Eval. 2022; 2(4):100089. https://doi.org/10.1016/j.tbench.2023.100089.
