J Korean Med Sci.
2024 Apr;39(16):e148. 10.3346/jkms.2024.39.e148.
Patient-Friendly Discharge Summaries in Korea Based on ChatGPT: Software Development and Validation
- Affiliations
-
- 1College of Nursing, Yonsei University, Seoul, Korea
- 2Department of Biomedical Systems Informatics, Yonsei University College of Medicine, Seoul, Korea
- 3Department of Surgery, Yonsei University College of Medicine, Seoul, Korea
- KMID: 2555478
- DOI: http://doi.org/10.3346/jkms.2024.39.e148
Abstract
- Background
Although discharge summaries in patient-friendly language can enhance patient comprehension and satisfaction, they can also increase medical staff workload. Using a large language model, we developed and validated software that generates a patient-friendly discharge summary.
Methods
We developed and tested the software using 100 discharge summary documents, 50 for patients with myocardial infarction and 50 for patients treated in the Department of General Surgery. For each document, three new summaries were generated using three different prompting methods (Zero-shot, One-shot, and Few-shot) and graded using a 5-point Likert Scale regarding factuality, comprehensiveness, usability, ease, and fluency. We compared the effects of different prompting methods and assessed the relationship between input length and output quality.
Results
The mean overall scores differed across prompting methods (4.19 ± 0.36 in Few-shot, 4.11 ± 0.36 in One-shot, and 3.73 ± 0.44 in Zero-shot; P < 0.001). Post-hoc analysis indicated that the scores were higher with Few-shot and One-shot prompts than in zero-shot prompts, whereas there was no significant difference between Few-shot and One-shot prompts. The overall proportion of outputs that scored ≥ 4 was 77.0% (95% confidence interval: 68.8–85.3%), 70.0% (95% confidence interval [CI], 61.0–79.0%), and 32.0% (95% CI, 22.9–41.1%) with Few-shot, One-shot, and Zero-shot prompts, respectively. The mean factuality score was 4.19 ± 0.60 with Few-shot, 4.20 ± 0.55 with One-shot, and 3.82 ± 0.57 with Zero-shot prompts. Input length and the overall score showed negative correlations in the Zero-shot (r = −0.437, P < 0.001) and One-shot (r = −0.327, P < 0.001) tests but not in the Few-shot (r = −0.050, P = 0.625) tests.
Conclusion
Large-language models utilizing Few-shot prompts generally produce acceptable discharge summaries without significant misinformation. Our research highlights the potential of such models in creating patient-friendly discharge summaries for Korean patients to support patient-centered care.
Keyword
Figure
-
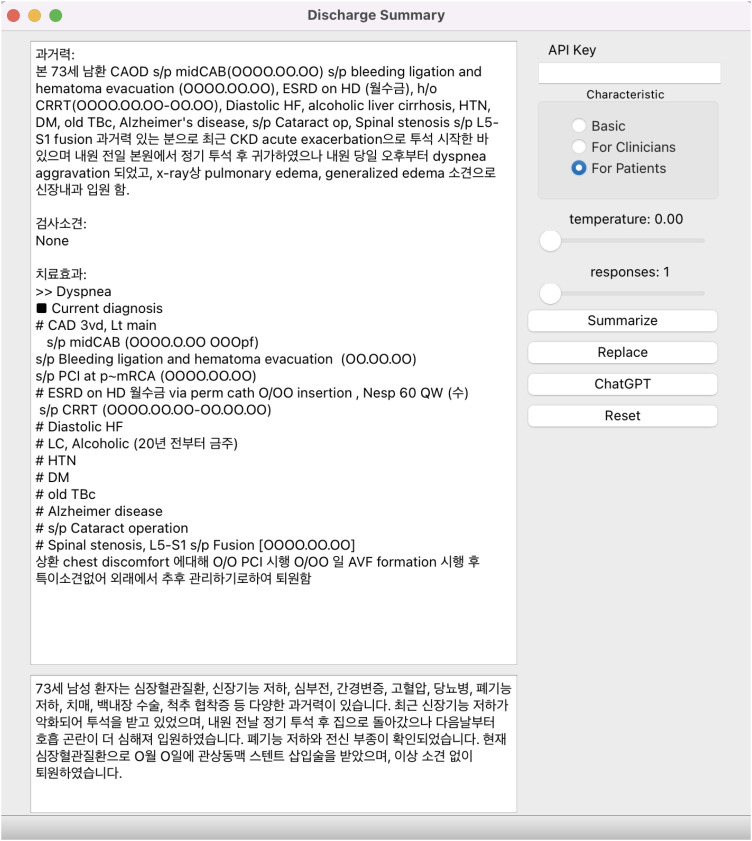
Fig. 1 Example of ‘Patient-Friendly Discharge Summary-Generating Software.’
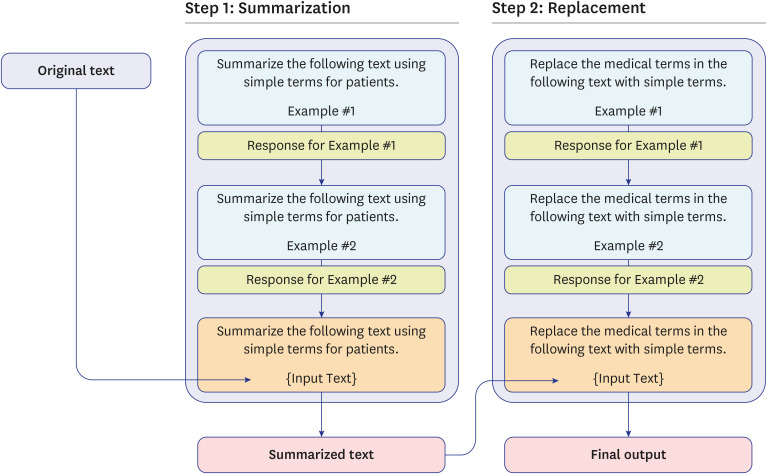
Fig. 2 Prompt design. The actual prompts were typed in Korean, as instructions in English resulted in English output in some cases. Supplementary Table 1 shows details of the instructions and examples of each step.
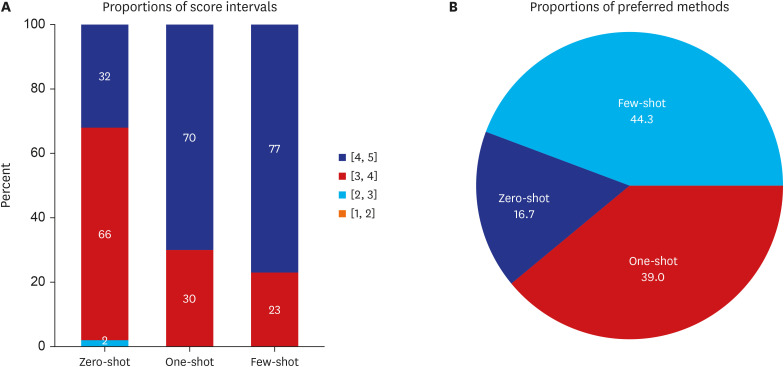
Fig. 3 Proportions of score intervals and preferred methods. (A) Proportions of score intervals. (B) Proportions of preferred methods.
Cited by 1 articles
-
Generative AI-Based Nursing Diagnosis and Documentation Recommendation Using Virtual Patient Electronic Nursing Record Data
Hongshin Ju, Minsul Park, Hyeonsil Jeong, Youngjin Lee, Hyeoneui Kim, Mihyeon Seong, Dongkyun Lee
Healthc Inform Res. 2025;31(2):156-165. doi: 10.4258/hir.2025.31.2.156.
Reference
-
1. Sorita A, Robelia PM, Kattel SB, McCoy CP, Keller AS, Almasri J, et al. The ideal hospital discharge summary: a survey of U.S. physicians. J Patient Saf. 2021; 17(7):e637–e644. PMID: 28885382.2. Lin R, Gallagher R, Spinaze M, Najoumian H, Dennis C, Clifton-Bligh R, et al. Effect of a patient-directed discharge letter on patient understanding of their hospitalisation. Intern Med J. 2014; 44(9):851–857. PMID: 24863954.3. Gaffney A, Woolhandler S, Cai C, Bor D, Himmelstein J, McCormick D, et al. Medical documentation burden among US office-based physicians in 2019: a national study. JAMA Intern Med. 2022; 182(5):564–566. PMID: 35344006.4. Tajirian T, Stergiopoulos V, Strudwick G, Sequeira L, Sanches M, Kemp J, et al. The influence of electronic health record use on physician burnout: cross-sectional survey. J Med Internet Res. 2020; 22(7):e19274. PMID: 32673234.5. Kim YG, Jung K, Park YT, Shin D, Cho SY, Yoon D, et al. Rate of electronic health record adoption in South Korea: a nation-wide survey. Int J Med Inform. 2017; 101:100–107. PMID: 28347440.6. OpenAI. Introducing ChatGPT. Updated 2022. Accessed August 14, 2023. https://openai.com/blog/chatgpt .7. Kung TH, Cheatham M, Medenilla A, Sillos C, De Leon L, Elepaño C, et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLOS Digit Health. 2023; 2(2):e0000198. PMID: 36812645.8. Sarraju A, Bruemmer D, Van Iterson E, Cho L, Rodriguez F, Laffin L. Appropriateness of cardiovascular disease prevention recommendations obtained from a popular online chat-based artificial intelligence model. JAMA. 2023; 329(10):842–844. PMID: 36735264.9. Ayers JW, Poliak A, Dredze M, Leas EC, Zhu Z, Kelley JB, et al. Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum. JAMA Intern Med. 2023; 183(6):589–596. PMID: 37115527.10. Nayak A, Alkaitis MS, Nayak K, Nikolov M, Weinfurt KP, Schulman K. Comparison of history of present illness summaries generated by a chatbot and senior internal medicine residents. JAMA Intern Med. 2023; 183(9):1026–1027. PMID: 37459091.11. Cook JL, Fioratou E, Davey P, Urquhart L. Improving patient understanding on discharge from the short stay unit: an integrated human factors and quality improvement approach. BMJ Open Qual. 2022; 11(3):e001810.12. Newnham H, Barker A, Ritchie E, Hitchcock K, Gibbs H, Holton S. Discharge communication practices and healthcare provider and patient preferences, satisfaction and comprehension: a systematic review. Int J Qual Health Care. 2017; 29(6):752–768. PMID: 29025093.13. Patel SB, Lam K. ChatGPT: the future of discharge summaries? Lancet Digit Health. 2023; 5(3):e107–e108. PMID: 36754724.14. OpenAI platform. Models. Updated 2023. Accessed August 14, 2023. https://platform.openai.com/docs/models .15. OpenAI platform. Quickstart. Updated 2023. Accessed August 14, 2023. https://platform.openai.com/docs/quickstart .16. Brown T, Mann B, Ryder N, Subbiah M, Kaplan JD, Dhariwal P, et al. Language models are few-shot learners. Adv Neural Inf Process Syst. 2020; 33:1877–1901.17. Tang L, Sun Z, Idnay B, Nestor JG, Soroush A, Elias PA, et al. Evaluating large language models on medical evidence summarization. NPJ Digit Med. 2023; 6(1):158. PMID: 37620423.18. Deroy A, Ghosh K, Ghosh S. How ready are pre-trained abstractive models and LLMs for legal case judgement summarization? ArXiv.19. OpenAI platform. Introduction. Updated 2023. Accessed August 14, 2023. https://platform.openai.com/docs/introduction .20. Mead N, Bower P. Patient-centredness: a conceptual framework and review of the empirical literature. Soc Sci Med. 2000; 51(7):1087–1110. PMID: 11005395.21. Epstein RM, Street RL Jr. The values and value of patient-centered care. Ann Fam Med. 2011; 9(2):100–103. PMID: 21403134.22. Ji Z, Lee N, Frieske R, Yu T, Su D, Xu Y, et al. Survey of hallucination in natural language generation. ACM Comput Surv. 2023; 55(12):1–38.23. Bang Y, Cahyawijaya S, Lee N, Dai W, Su D, Wilie B, et al. A multitask, multilingual, multimodal evaluation of ChatGPT on reasoning, hallucination, and interactivity. ArXiv.24. Lin CY, Hovy E. Automatic evaluation of summaries using n-gram co-occurrence statistics. In : Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics; May 27, 2003-June 1, 2003; Edmonton, Canada. Stroudsburg, PA, USA: Association for Computational Linguistics;2003. p. 150–157.25. Hanna M, Bojar O. A fine-grained analysis of BERTScore. Barrault L, Bojar O, Bougares F, Chatterjee R, Costa-jussa MR, Federmann C, editors. Proceedings of the Sixth Conference on Machine Translation. Stroudsburg, PA, USA: Association for Computational Linguistics;2021. p. 507–517.26. Banerjee S, Lavie A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In : Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization; June 2005; Ann Arbor, MI, USA. Stroudsburg, PA, USA: Association for Computational Linguistics;2005. p. 65–72.27. Papineni K, Roukos S, Ward T, Zhu WJ. Bleu: a method for automatic evaluation of machine translation. In : Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics; July 6-12, 2002; Philadelphia, PA, USA. Stroudsburg, PA, USA: Association for Computational Linguistics;2002. p. 311–318.28. Luo J, Li T, Wu D, Jenkin M, Liu S, Dudek G. Hallucination detection and hallucination mitigation: an investigation. ArXiv. 2024; DOI: 10.48550/arXiv.2401.08358.29. Kim S. In the era of ChatGPT, can medical artificial intelligence replace the doctor? Korean J Med. 2023; 98(3):99–101.30. Doskaliuk B, Zimba O. Beyond the keyboard: academic writing in the era of ChatGPT. J Korean Med Sci. 2023; 38(26):e207. PMID: 37401498.31. Thirunavukarasu AJ, Ting DS, Elangovan K, Gutierrez L, Tan TF, Ting DS. Large language models in medicine. Nat Med. 2023; 29(8):1930–1940. PMID: 37460753.32. Preiksaitis C, Sinsky CA, Rose C. ChatGPT is not the solution to physicians’ documentation burden. Nat Med. 2023; 29(6):1296–1297. PMID: 37169865.33. Singhal K, Azizi S, Tu T, Mahdavi SS, Wei J, Chung HW, et al. Large language models encode clinical knowledge. Nature. 2023; 620(7972):172–180. PMID: 37438534.34. Singhal K, Tu T, Gottweis J, Sayres R, Wulczyn E, Hou L, et al. Towards expert-level medical question answering with large language models. ArXiv.35. Chowdhery A, Narang S, Devlin J, Bosma M, Mishra G, Roberts A, et al. Palm: scaling language modeling with pathways. J Mach Learn Res. 2023; 24(240):1–113.36. Anil R, Dai AM, Firat O, Johnson M, Lepikhin D, Passos A, et al. Palm 2 technical report. ArXiv.37. Li T, Shetty S, Kamath A, Jaiswal A, Jiang X, Ding Y, et al. CancerGPT for few shot drug pair synergy prediction using large pretrained language models. NPJ Digit Med. 2024; 7(1):40. PMID: 38374445.38. Deik A. Potential benefits and perils of incorporating ChatGPT to the movement disorders clinic. J Mov Disord. 2023; 16(2):158–162. PMID: 37258279.39. Rau A, Rau S, Zoeller D, Fink A, Tran H, Wilpert C, et al. A context-based chatbot surpasses trained radiologists and generic ChatGPT in following the ACR appropriateness guidelines. Radiology. 2023; 308(1):e230970. PMID: 37489981.40. Russe MF, Fink A, Ngo H, Tran H, Bamberg F, Reisert M, et al. Performance of ChatGPT, human radiologists, and context-aware ChatGPT in identifying AO codes from radiology reports. Sci Rep. 2023; 13(1):14215. PMID: 37648742.41. OpenAI. GPT-4. Updated 2023. Accessed August 14, 2023. https://openai.com/research/gpt-4 .42. Google. Bard. Updated 2023. Accessed August 14, 2023. https://bard.google.com .43. Chen L, Zaharia M, Zou J. How is ChatGPT’s behavior changing over time? ArXiv.44. Chang Y, Wang X, Wang J, Wu Y, Yang L, Zhu K, et al. A survey on evaluation of large language models. ACM Trans Intell Syst Technol. 2024; 15(3):39.45. OpenAI. API data usage policies. Updated 2023. Accessed August 14, 2023. https://openai.com/policies/api-data-usage-policies .
- Full Text Links
-
- Actions
-
Cited
- CITED
-
- Close
- Share
-
- Similar articles
-
- Accuracy, appropriateness, and readability of ChatGPT-4 and ChatGPT-3.5 in answering pediatric emergency medicine post-discharge questions
- Application of ChatGPT for Orthopedic Surgeries and Patient Care
- In the Era of ChatGPT, Can Medical Artificial Intelligence Replace the Doctor?
- Toward the Automatic Generation of the Entry Level CDA Documents
- Can we trust AI chatbots’ answers about disease diagnosis and patient care?
