J Korean Soc Med Inform.
2009 Sep;15(3):247-254.
The Feasibility of Using Classification and Identification Techniques to Auto-Assess the Quality of Health Information on the Web
- Affiliations
-
- 1Institute of Biomedical Informatics, National Yang-Ming University, Taiwan. polun@ym.edu.tw
- 2Armed Forces Taichung General Hospital, Taiwan.
- 3Department of Information Technology, Taipei City Government, Taiwan.
Abstract
OBJECTIVE
An automatic detection tool was created for examining health-related webpage quality we went further by examining its feasibility and performance.
METHODS
We developed an automatic detection system to auto-assess the authorship quality indicator of an health-related information webpage for governmental websites in Taiwan. The system was integrated with the Chinese word segmentation system developed by the Academia Sinica in Taiwan and the SVM(light), which serve as an SVM (Support Vector Machine) Classifiers and a method of information extraction and identification. The system was coded in Visual Basic 6.0, using SQL 2000.
RESULTS
We developed the first Chinese automatic webpage classification and information identifier to evaluate the quality of web information. The sensitivity and specificity of the classifier on the training set of webpages were both as high as 100% and only one health webpage in the test set was misclassified, due to the fact that it contained both health and non-health information content. The sensitivity of our authorship identifier is 75.3%, with a specificity of 87.9%.
CONCLUSION
The technical feasibility of auto-assessment for the quality of health information on the web is acceptable. Although it is not sufficient to assure the total quality of web contents, it is good enough to be used to support the entire quality assurance program.
MeSH Terms
Figure
-

Figure 1 Process of system operations which consist two key components: classifier to auto-identify health websites and extractor to identify quality contents for assessment.

Figure 2 The system structures.
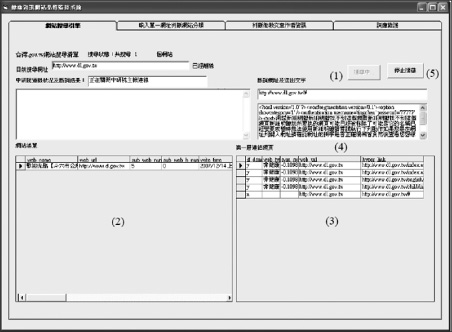
Figure 3 The screenshot of crawler.

Figure 4 The snapshot of classifier.
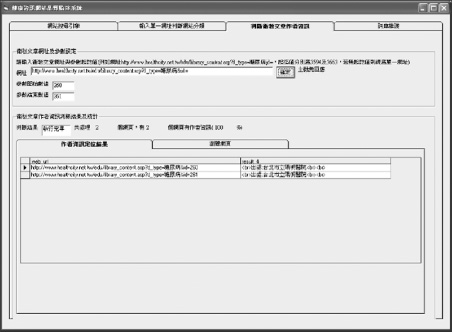
Figure 5 The snapshot of authorship identification.
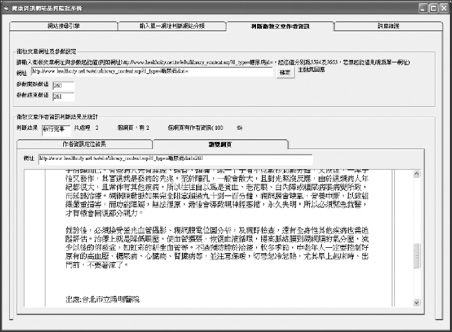
Figure 6 The snapshot of web contents after auto-assessment.
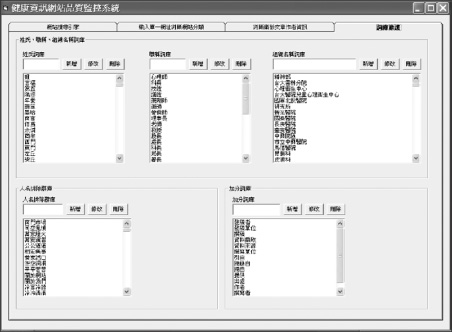
Figure 7 The snapshot of corpus maintenance.
Reference
-
1. Fox S. The Engaged E-patient Population. Pew Internet & American Life Project. 2008. 08. 26. Accessed on August 18, 2009. Available at: http://www.pewinternet.org/Reports/2008/The-Engaged-Epatient-Population.aspx.2. eHealth Code of Ethics. Accessed on August 18, 2009. Available at: http://www.hieurope.co.uk/files/2000/ehealth_code.pdf.3. Rozmovits L, Ziebland S. What do patients with prostate or breast cancer want from an internet site? A qualitative study of information needs. Patient Education and Counselling. 2004. 53:57–64.
Article4. Gaudinat A, Ruch P, Joubert M, et al. Health search engine with e-document analysis for reliable search results. International Journal of Medical Informatics. 2006. 75(1):73–85.
Article5. Kemper DW. Hi-Ethics: Tough principles for earning consumer trust. 2001. In : URAC/Internet Healthcare Coalition;6. HON code. Accessed on August 18, 2009. Available at: http://www.hon.ch/HONcode/.7. Wang Y, Liu Z. Automatic detecting indicators for quality of health information on the web. International Journal of Medical Informatics. 2007. 76(8):575–582.
Article8. Wang Y, Richard R. Rule-based automatic criteria detection for assessing quality of online health information. 2007. In : The International Conference Addressing Information Technology and Communications in Health (ITCH); 15–18.9. The Natual Language Processing Lab, National Taiwan University, Taiwan. Accessed on September 25, 2009. Available at: http://nlg.csie.ntu.edu.tw/advisor.html.10. Support Vector Machine. Accessed on Septermber 25, 2009. Available at: http://en.wikipedia.org/wiki/Support_vector_machine.11. SVMlight. 2006. Accessed on August 18, 2009. Available at: http://svmlight.joachims.org/.12. TF-IDF. Accessed on September 25, 2009. Available at: http://en.wikipedia.org/wiki/Tf-idf.13. The Chinese Word Segmentation System. Accessed on September 25, 2009. Available at: http://ckipsvr.iis.sinica.edu.tw/.14. Taichung Veterans General Hospital. Accessed on Septermber 25, 2009. Available at: http://www.vghtc.gov.tw/.15. The Taiwan National Health Insurance Bureau. Accessed on September 25, 2009. Available at: http://www.nhi.gov.tw/.16. Price SL, Hersh WR. filtering web pages for quality indicators: an empirical approach to finding high quality consumer health information on the world wide web. 1999. In : Proceeding of AMIA Symposium; 911–915.17. Wang Y, Liu Z. Automatic detecting indicators for quality of health information on the web. International Journal of Medical Informatics. 2007. 76(8):575–582.
Article18. A Quality Health Information Gateway for Australian. Accessed on September 25, 2009. Available at: http://www.healthinsite.gov.au/.19. Kim P, Eng TR, Deering MJ, et al. Published criteria for evaluating health related websites: review. BMJ. 1999. 318:647–649.
Article20. Eysenbach G, Powell J, Kuss O, et al. Empirical studies assessing the quality of health information for consumers on the world wide web: a system review. JAMA. 2002. 287(20):2691–2700.
Article
- Full Text Links
-
- Actions
-
Cited
- CITED
-
- Close
- Share
-
- Similar articles
-
- Application of Evaluation Criteria for Web sites to Sexuality Education
- Development of a Health Information Web Site Evaluation Categories with Items for Diabetes Mellitus
- Analysis of the Accessibility and Quality of Information of Arthritis-Related Internet Web Sites in Korea
- Criteria for the websites in Korean with health information on the Internet
- Development of a Web-Site Providing Health Related Information for the Disabled
