Healthc Inform Res.
2012 Mar;18(1):65-73. 10.4258/hir.2012.18.1.65.
An Evaluation of Multiple Query Representations for the Relevance Judgments used to Build a Biomedical Test Collection
- Affiliations
-
- 1Department of Biomedical Engineering, Seoul National University College of Medicine, Seoul, Korea. jinchoi@snu.ac.kr
- KMID: 2166619
- DOI: http://doi.org/10.4258/hir.2012.18.1.65
Abstract
OBJECTIVES
The purpose of this study is to validate a method that uses multiple queries to create a set of relevance judgments used to indicate which documents are pertinent to each query when forming a biomedical test collection.
METHODS
The aspect query is the major concept of this research; it can represent every aspect of the original query with the same informational need. Manually generated aspect queries created by 15 recruited participants where run using the BM25 retrieval model in order to create aspect query based relevance sets (QRELS). In order to demonstrate the feasibility of these QRELSs, The results from a 2004 genomics track run supported by the National Institute of Standards and Technology (NIST) were used to compute the mean average precision (MAP) based on Text Retrieval Conference (TREC) QRELSs and aspect-QRELSs. The rank correlation was calculated using both Kendall's and Spearman's rank correlation methods.
RESULTS
We experimentally verified the utility of the aspect query method by combining the top ranked documents retrieved by a number of multiple queries which ranked the order of the information. The retrieval system correlated highly with rankings based on human relevance judgments.
CONCLUSIONS
Substantial results were shown with high correlations of up to 0.863 (p < 0.01) between the judgment-free gold standard based on the aspect queries and the human-judged gold standard supported by NIST. The results also demonstrate that the aspect query method can contribute in building test collections used for medical literature retrieval.
Keyword
MeSH Terms
Figure
-
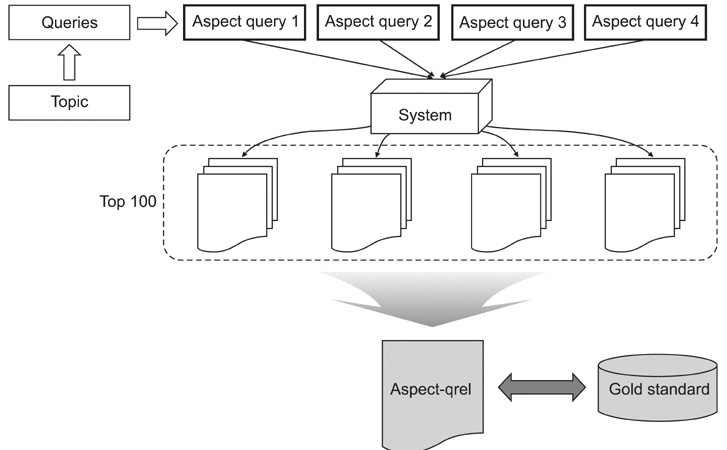
Figure 1 Block diagram of experimental methodology.
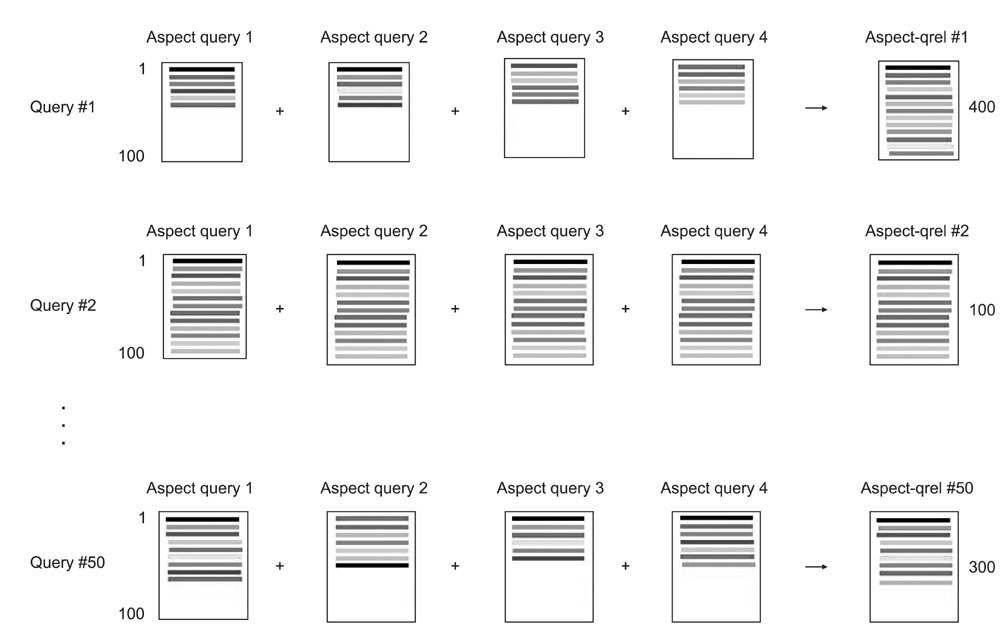
Figure 2 Methodological diagram for generating aspect-qrels.
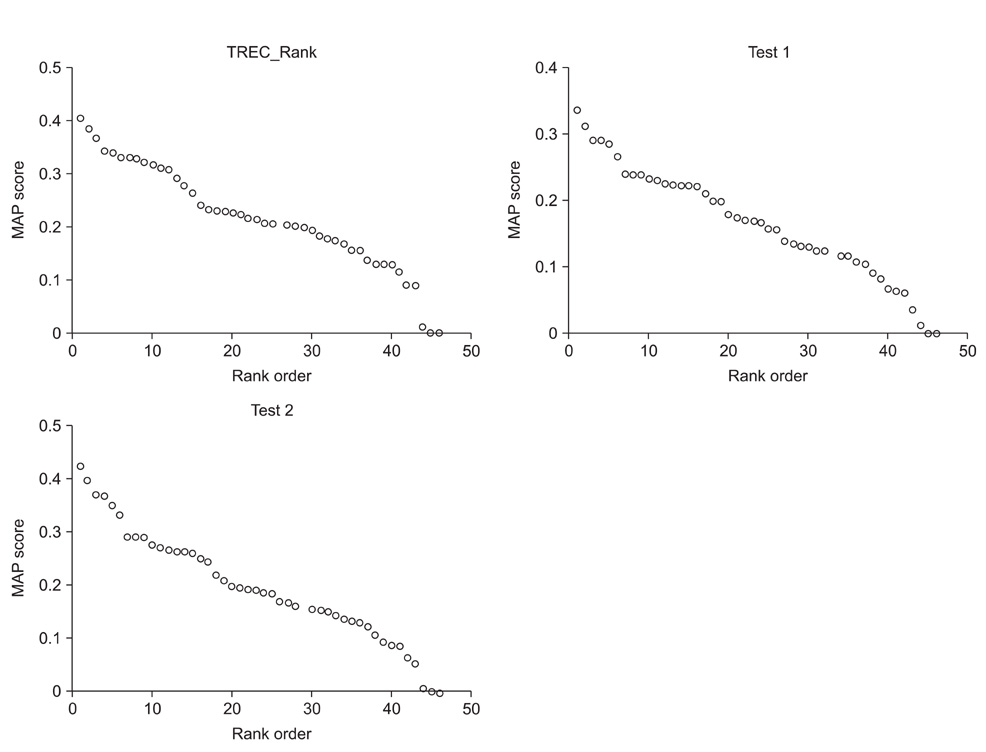
Figure 3 System rankings among the original Text Retrieval Conference (TREC) rankings on mean average precision (MAP) and aspect-qrel based rankings on aMAP, test 1 and test 2.
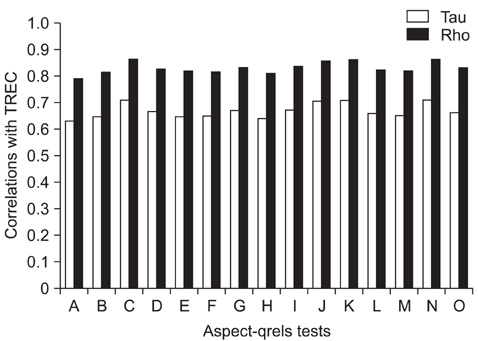
Figure 4 Experimental results for rank correlations among aspect-qrels: Kendall's tau and Spearman's rho coefficients. TREC: Text Retrieval Conference.
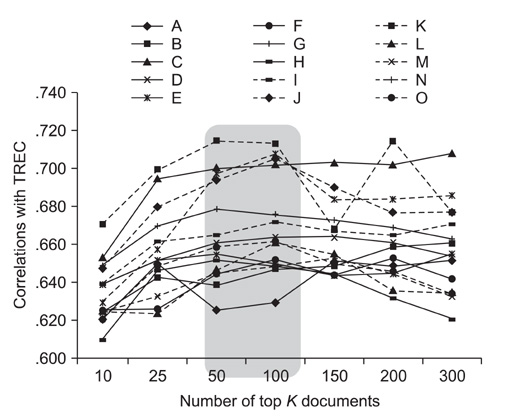
Figure 5 The effect of the number of documents collected per aspect during aspect-qrel creation. TREC: Text Retrieval Conference.
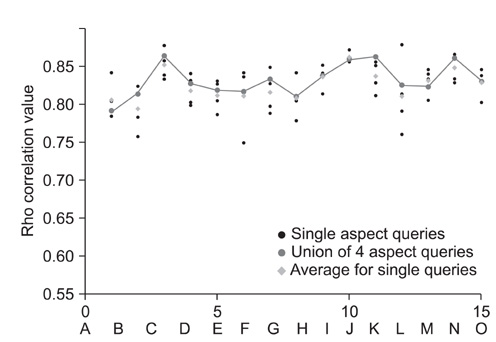
Figure 6 Rho correlation between MAP and aMAP calculated from individual aspect qrels. MAP: mean average precision, aMAP: aspect-qrels MAP.
Reference
-
1. Sanderson M, Braschler M. Best practices for test collection creation and information retrieval system evaluation. 2009. Pisa, Italy: TrebleCLEF;Technical report no.: D4.2.2. Voorhees EM, Tice DM. Building a question answering test collection. Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. 2000. 200–207.
Article3. Oard DW, Soergel D, Doermann D, Huang X, Murray GC, Wang J, Ramabhadran B, Franz M, Gustman S, Mayfield J, Kharevych L, Strassel S. Building an information retrieval test collection for spontaneous conversational speech. Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. 2004. 41–48.
Article4. Hersh W, Buckley C, Leone TJ, Hickam D. OHSUMED: an interactive retrieval evaluation and new large test collection for research. Proceedings of the 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. 1994. 192–201.
Article5. Heppin KF. MedEval: a Swedish medical test collection with doctors and patients user groups. Proceedings of the NAACL HLT 2010 Second Louhi Workshop on Text and Data Mining of Health Document. 2010. 1–7.6. Efron M. Using multiple query aspects to build test collections without human relevance judgments. Proceedings of the 31th European Conference on IR Research on Advances in Information Retrieval. 2009. 276–287.
Article7. Sanderson M, Joho H. Forming test collections with no system pooling. Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. 2004. 33–40.
Article8. Soboroff I, Nicholas C, Cahan P. Ranking retrieval systems without relevance judgments. Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. 2001. 66–73.
Article9. Wu S, Crestani F. Methods for ranking information retrieval systems without relevance judgments. Proceedings of the 2003 ACM Symposium on Applied Computing. 2003. 811–816.
Article10. Grady C, Lease M. Crowdsourcing document relevance assessment with mechanical turk. Proceedings of the NAACL HLT Workshop on Creating Speech and Language Data with Amazon's Mechanical Turk. 2010. 172–179.11. Cao YG, Ely J, Antieau L, Yu H. Evaluation of the clinical question answering presentation. Proceedings of the Workshop on Current Trends in Biomedical Natural Language Processing. 2009. 171–178.
Article12. Luo G. Design and evaluation of the iMed intelligent medical search engine. Proceedings of the IEEE International Conference on Data Engineering. 2009. 1379–1390.
Article13. Text retrieval conference (TREC) [Internet]. National Institute of Sandards and Technology (NIST). c2012. cited at 2011 Oct 17. Gaithersburg (MD): NIST;Available from: http://trec.nist.gov/.14. Si L, Lu J, Callan J. Combining multiple resources, evidence and criteria for genomic information retrieval. Proceedings of the Fifteenth Text Retrieval Conference (TREC). 2006.15. Yin X, Huang X, Li Z. Promoting ranking diversity for biomedical information retrieval using wikipedia. Proceedings of the 32nd European Conference on Advances in Information Retrieval. 2010. 495–507.
Article16. Yin X, Huang JX, Zhou X, Li Z. A survival modeling approach to biomedical search result diversification using wikipedia. Proceedings of the 32nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. 2010. 901–902.
Article17. TREC genomics track [Internet]. National Science Foundation Information Technology Research. c2008. cited at 2011 Oct 17. Arlington (VA): National Science Foundation Information Technology Research;Available from: http://ir.ohsu.edu/genomics/.18. Hersh WR. Report on the TREC 2004 genomics track. ACM SIGIR Forum. 2005. 39:21–24.
Article19. Korean Medical Library Engine [Internet]. c2011. cited at 2011 Jul 20. Seoul, Korea: Korean Medical Library Engine;Available from: http://www.kmle.co.kr/.20. Medical Subject Headings [Internet]. National Library of Medicine. c2011. cited at 2011 Jul 20. Bethesda (MD): National Library Medicine;Available from: http://www.nlm.nih.gov/mesh/MBrowser.html.
- Full Text Links
-
- Actions
-
Cited
- CITED
-
- Close
- Share
-
- Similar articles
-
- Evaluation of Term Ranking Algorithms for Pseudo-Relevance Feedback in MEDLINE Retrieval
- Educational Program Evaluation System in a Medical School
- Effective Query Expansion using Condensed UMLS Metathesaurus for Medical Information Retrieval
- Actual Judgment of Criminal Responsibility as Seen Through the Criminal Psychiatric Examination of a Psychiatric Hospital
- Improving the CONTES method for normalizing biomedical text entities with concepts from an ontology with (almost) no training data
