Healthc Inform Res.
2012 Mar;18(1):18-28. 10.4258/hir.2012.18.1.18.
Improving the Performance of Text Categorization Models used for the Selection of High Quality Articles
- Affiliations
-
- 1Department of Biomedical Engineering, Seoul National University College of Medicine, Seoul, Korea. jinchoi@snu.ac.kr
- KMID: 2166614
- DOI: http://doi.org/10.4258/hir.2012.18.1.18
Abstract
OBJECTIVES
Machine learning systems can considerably reduce the time and effort needed by experts to perform new systematic reviews (SRs). This study investigates categorization models, which are trained on a combination of included and commonly excluded articles, which can improve performance by identifying high quality articles for new procedures or drug SRs.
METHODS
Test collections were built using the annotated reference files from 19 procedure and 15 drug systematic reviews. The classification models, using a support vector machine, were trained by the combined even data of other topics, excepting the desired topic. This approach was compared to the combination of included and commonly excluded articles with the combination of included and excluded articles. Accuracy was used for the measure of comparison.
RESULTS
On average, the performance was improved by about 15% in the procedure topics and 11% in the drug topics when the classification models trained on the combination of articles included and commonly excluded, were used. The system using the combination of included and commonly excluded articles performed better than the combination of included and excluded articles in all of the procedure topics.
CONCLUSIONS
Automatically rigorous article classification using machine learning can reduce the workload of experts when they perform systematic reviews when the topic-specific data are scarce. In particular, when the combination of included and commonly excluded articles is used, this system will be more effective.
Keyword
Figure
-
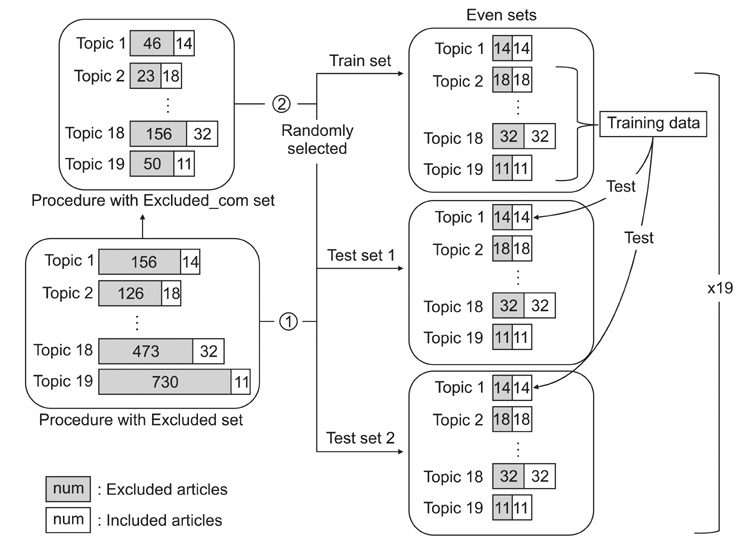
Figure 1 Evaluation processes of one topic.
Cited by 1 articles
-
Clinical Care Improvement with Use of Health Information Technology Focusing on Evidence Based Medicine
Rezaei Hachesu Peyman, Maryam Ahmadi, Rezapoor Aziz, Salahzadeh Zahra, Sadughi Farahnaz, Maroufi Nader
Healthc Inform Res. 2012;18(3):164-170. doi: 10.4258/hir.2012.18.3.164.
Reference
-
1. Sackett DL, Rosenberg WM, Gray JA, Haynes RB, Richardson WS. Evidence based medicine: what it is and what it isn't. BMJ. 1996. 312:71–72.
Article2. Aphinyanaphongs Y, Tsamardinos I, Statnikov A, Hardin D, Aliferis CF. Text categorization models for high-quality article retrieval in internal medicine. J Am Med Inform Assoc. 2005. 12:207–216.
Article3. Matwin S, Kouznetsov A, Inkpen D, Frunza O, O'Blenis P. A new algorithm for reducing the workload of experts in performing systematic reviews. J Am Med Inform Assoc. 2010. 17:446–453.
Article4. The Cochrane Library. About Cochrane systematic reviews and protocols [Internet]. c2012. cited at 2012 Mar 13. West Sussex, UK: John Wiley & Sons, Ltd.;Available from: http://www.thecochranelibrary.com/view/0/AboutCochraneSystematicReviews.html.5. Cohen AM, Ambert K, McDonagh M. Cross-topic learning for work prioritization in systematic review creation and update. J Am Med Inform Assoc. 2009. 16:690–704.
Article6. Committee for New Health Technology Assessment. nHTA. c2012. cited at 2012 Mar 13. Seoul, Korea: Ministry of Health and Welfare;Available from: http://neca.re.kr/nHTA/english/.7. Koch G. No improvement - still less than half of the Cochrane reviews are up to date. 2006. In : 14th Cochrane Colloquium;8. Chalmers I, Glasziou P. Avoidable waste in the production and reporting of research evidence. Lancet. 2009. 374:86–89.
Article9. Cohen AM, Hersh WR, Peterson K, Yen PY. Reducing workload in systematic review preparation using automated citation classification. J Am Med Inform Assoc. 2006. 13:206–219.
Article10. Cohen AM. Systematic drug class review gold standard data [Internet]. c2010. cited at 2011 May 16. Portland (OR): Oregon Health & Science University;Available from: http://davinci.ohsu.edu/~cohenaa/systematic-drug-class-review-data.html.11. Onix text retrieval toolkit: API reference [Internet]. c2000. cited at 2011 May 21. Provo (UT): Lextek International;Available from: http://www.lextek.com/manuals/onix/stopwords1.html.12. Porter MF. An algorithm for suffix stripping. Program. 1980. 14:130–137.
Article13. Cohen AM. Optimizing feature representation for automated systematic review work prioritization. AMIA Annu Symp Proc. 2008. 121–125.14. Joachims T. Text categorization with support vector machines: learning with many relevant features. Proceedings of the 10th European Conference on Machine Learning. 1998. –137. –142.
Article15. Kilicoglu H, Demner-Fushman D, Rindflesch TC, Wilczynski NL, Haynes RB. Towards automatic recognition of scientifically rigorous clinical research evidence. J Am Med Inform Assoc. 2009. 16:25–31.
Article16. Joachims T. Support vector machine: SVMlight [Internet]. c2008. cited at 2011 May 20. Ithaca (NY): Cornell University;Available from: http://svmlight.joachims.org/.17. Joachims T. Scholkopf B, Burges CJ, Smola AJ, editors. Making large-scale support vector machine learning practical. Advances in kernel methods. 1999. Cambridge (MA): MIT Press;169–184.
Article18. Lee YH, Cheng TH, Lan CW, Wei CP, Hu PJ. Overcoming small-size training set problem in content-based recommendation: a collaboration-based training set expansion approach. Proceedings of the 11th International Conference on Electronic Commerce. 2009. –99. –106.
Article
- Full Text Links
-
- Actions
-
Cited
- CITED
-
- Close
- Share
-
- Similar articles
-
- Text Mining in Biomedical Domain with Emphasis on Document Clustering
- Opinion: Strategy of Semi-Automatically Annotating a Full-Text Corpus of Genomics & Informatics
- The Acceptable Text Similarity Level in Manuscripts Submitted to Scientific Journals
- GPTZero Performance in Identifying Artificial Intelligence-Generated Medical Texts: A Preliminary Study
- Analysis of Media Articles on COVID-19 and Nurses Using Text Mining and Topic Modeling
